



Поиск в DC CMS
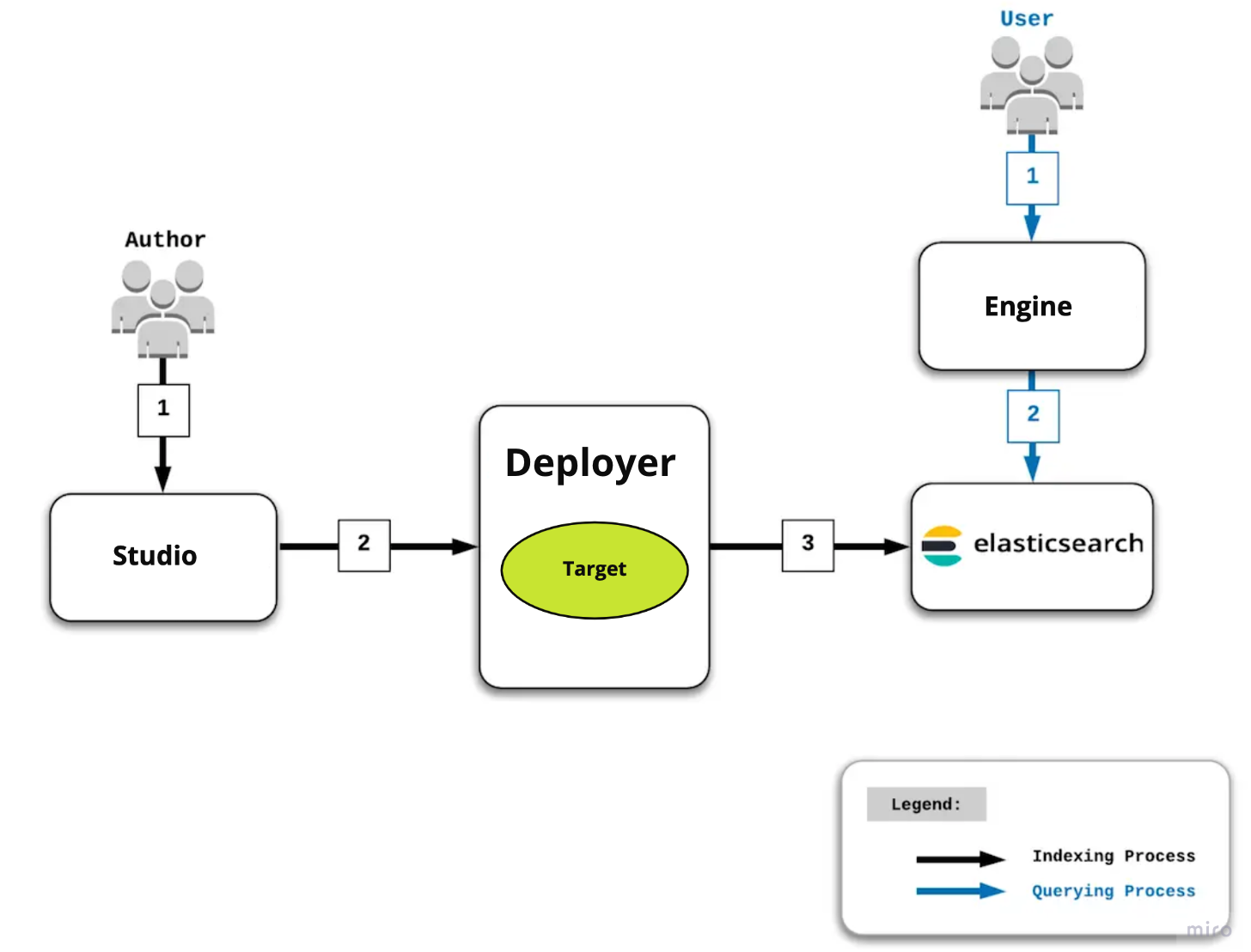
Логика работы сервиса поиска
Процесс запроса
1. Конечный пользователь запрашивает страницу или сервис-запрос в CMS Engine.
2. Компоненты CMS Engine, которым требуются запросы, отправляют запрос в Elastic Search, где к запросу будут добавлены простые фильтры, а затем выполнены.
Процесс индексации
1. Автор обновляет контент в Studio.
2. Studio уведомляет Deployer об изменениях в конкретной цели (Target), которая представляет собой комбинацию сайта/среды. Затем:
- При предварительном обновлении Deployer проверяет
sandboxи обрабатывает изменения (resolve changes), выполняя сравнение файлов между последней обработанной версией Git и последней версией в файлеsandbox. - При публикации Studio перемещает изменения в
published, а Deployer при доставке извлекает изменения.
3. Процессор цели (Target Processor) в Deployer отправляет запрос в Elastic Search с XML или содержимым для индексации.
-
Связь между CMS Studio и CMS Deployer
-
Studio уведомит Deployer об изменении содержимого.
-
Убедитесь, что Deployer извлекает изменения.
-
Если Deployer не получает никаких изменений, проверьте сетевое подключение и порты.
-
-
Связь между Deployer и Elastic search
-
У Deployer есть цель с поисковым процессором.
-
Убедитесь, что процессор настроен на правильный HOST, PORT для Elastic Search.
-
-
Связь между CMS Engine и Elastic Search
-
CMS Engine настроен на взаимодействие с Elastic Search.
-
Убедитесь, что CMS Engine настроен на правильный HOST, PORT для Elastic Search.
-
Просмотр файлов журнала
|
Компонент
|
Лог-файлы
|
|
cell text
|
CMS/logs/tomcat/catalina.out |
|
cell text
|
CMS/logs/deployer/deployer.out
CMS/logs/deployer/deployer-general.log
CMS/logs/deployer/{target}-{env}.log
|
|
cell text
|
CMS/logs/elasticsearch/elasticsearch.log |
|
cell text
|
CMS/logs/tomcat/catalina.out |
Настройка порта развертывания и эластичного порта поиска
CMS/bin/crafter-setenv.sh
Мониторинг хранилища Elastic Search
-
Не будет выделять "осколки" (shards) узлам (nodes), которые используют более 85% диска (влияет только на кластеры, а не на отдельные экземпляры).
-
Попытается переместить осколки с узла, у которого использование диска превышает 90 % (влияет только на кластеры, а не на отдельные экземпляры).
-
Применяет режим только для чтения для каждого индекса, имеющего один или несколько сегментов, выделенных на узле, у которого есть хотя бы один диск, превышающий 95% (влияет на любой экземпляр).
Caused by: ElasticsearchStatusException[Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];]]
В журнале поиска Elastic Search появится следующее сообщение:
[2019-04-02T16:10:14,520][WARN ][o.e.c.r.a.DiskThresholdMonitor] [uKHC0qA] flood stage disk watermark [95%] exceeded on [uKHC0qAFSrWZguNmsWhFiQ][uKHC0qA][INSTALL_DIR/data/indexes-es/nodes/0] free: 10.5gb[4.5%], all indices on this node will be marked read-only
OOTB возможности поиска:
- REST API запрос для выполнения поиска
search. -
Два типа поиска:
-
по
id - и по
аттрибуту (свойству)объекта.
-
-
Индексация XML и Binary Files
-
Обновление индекса
-
Удаление индекса
Для Разработки
cms/search/ElasticsearchService.java Реализация -
cms/search/ElasticsearchServiceImpl.java co.elastic.clients.elasticsearch через ElasticsearchClient.java CMS Engine
Чтобы выполнить запросы к контенту, используйте клиент, предоставляемый CMS Engine (имя бина (bean) searchClient), доступным из любого Groovy-скрипта.
Для создания запросов существует два подхода в зависимости от сложности запроса: Query DSL и Query Builders.
Query DSL
Следуя структуре, используемой ElasticSearch для REST API, этот метод идеален для простых или постоянных запросов, требующих минимальной конфигурации.
Поисковый запрос с использованием DSL:
// No imports are required for this method
// Execute the query using inline builders
def searchResponse = searchClient.search(r -> r
.query(q -> q
.bool(b -> b
.should(s -> s
.match(m -> m
.field('content-type')
.query(v -> v
.stringValue('/component/article')
)
)
)
.should(s -> s
.match(m -> m
.field('author')
.query(v -> v
.stringValue('My User')
)
)
)
)
)
, Map)
def itemsFound = searchResponse.hits().total().value()
def items = searchResponse.hits().hits()*.source()
return items
Query Builders
Используйте все классы, доступные в официальном пакете клиента ElasticSearch, чтобы создавать запросы. Этот метод позволяет использовать объекты-строители (builder objects) для разработки сложной логики конструирования запросов.
Поисковый запрос с использованием объектов-строителей:
// Import the required classes
import org.elasticsearch.client.elasticsearch.core.SearchRequest
def queryStatement = 'content-type:"/component/article" AND author:"My User"'
// Use the appropriate builders according to your query
def builder = new SearchRequest.Builder()
.query(q -> q
.queryString(s -> s
.query(queryStatement)
)
)
// Perform any additional changes to the builder, for example add pagination if required
if (pagination) {
builder
.from(pagination.offset)
.size(pagination.limit)
}
// Execute the query
def searchResponse = searchClient.search(builder.build(), Map)
def itemsFound = searchResponse.hits().total().value()
def items = searchResponse.hits().hits()*.source()
return items
Реализация фасетного поиска
Фасетный поиск можно осуществить при помощи агрегаций, чтобы предоставить пользователям возможность уточнить результаты поиска на основе одного или нескольких полей.
Виды фасетов
-
Мульти выбор - Такой фасет при выборе нескольких значений составит выборку в семантике "значение 1 или значение 2", иначе "значение 1 и значение 2".
На текущий момент такой фасет - фасет цвета, при выборе красного и черного цветов, будут возвращены продукты, которые имеют один из этих цветов. Если бы фасет цвета был не мультивыборным, то вернулись бы продукты у которых присутствуют оба эти цвета. -
Влияние на аггрегацию - Данные фасеты влияют/не влияют на выдачу фасетов. Так как фасеты строятся по отфильтрованный выборке, то при выборе пользователем набора параметров, которые приводят к нулевой выборке, список фасетов будет пустым. Для этого фасеты цены и цвета не изменяют результаты выдачи фасетов, если переданы как выбранные параметры. Но! все фасеты всегда влияют на выборку продуктов.
-
Иерархический - данный фасет для каждого значения вернет список дочерних значений. На данный момент это фасет категории.
Функционал поиска предоставляет ряд агрегаций, настроенных под характеристики полей в вашей модели или требования интерфейса пользователя для отображения данных.
В этой статье мы будем использовать базовую агрегацию terms для создания фасетного поиска, основанного на категоризации статей блога.

Первый шаг включает в себя определение полей для агрегации. В данном случае модель страницы “Статья” включает в себя поле “Categories”, значения которого извлекаются из таксономии сайта через источник данных. Поэтому название поля в индексе - categories.item.value_smv.
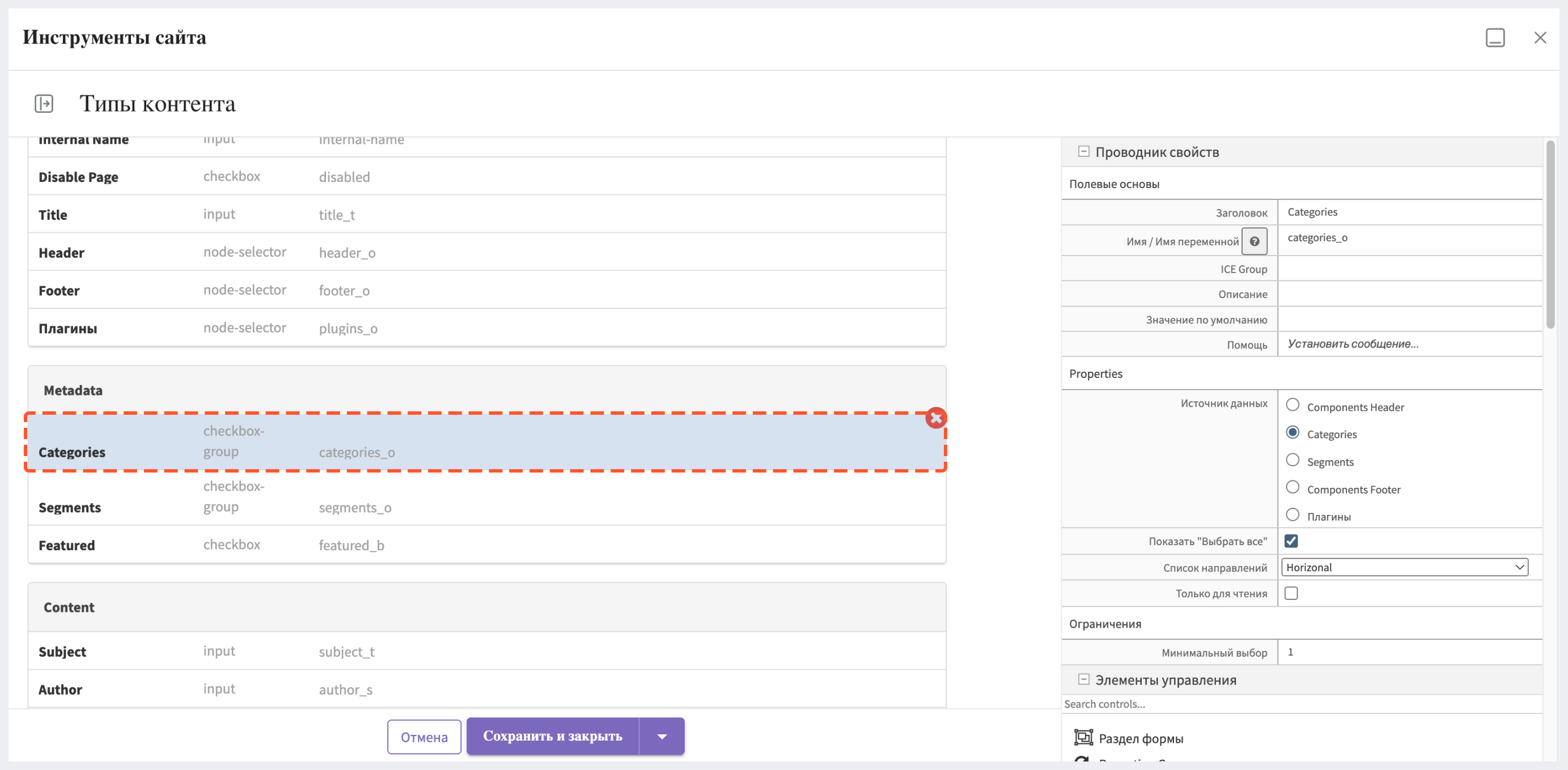
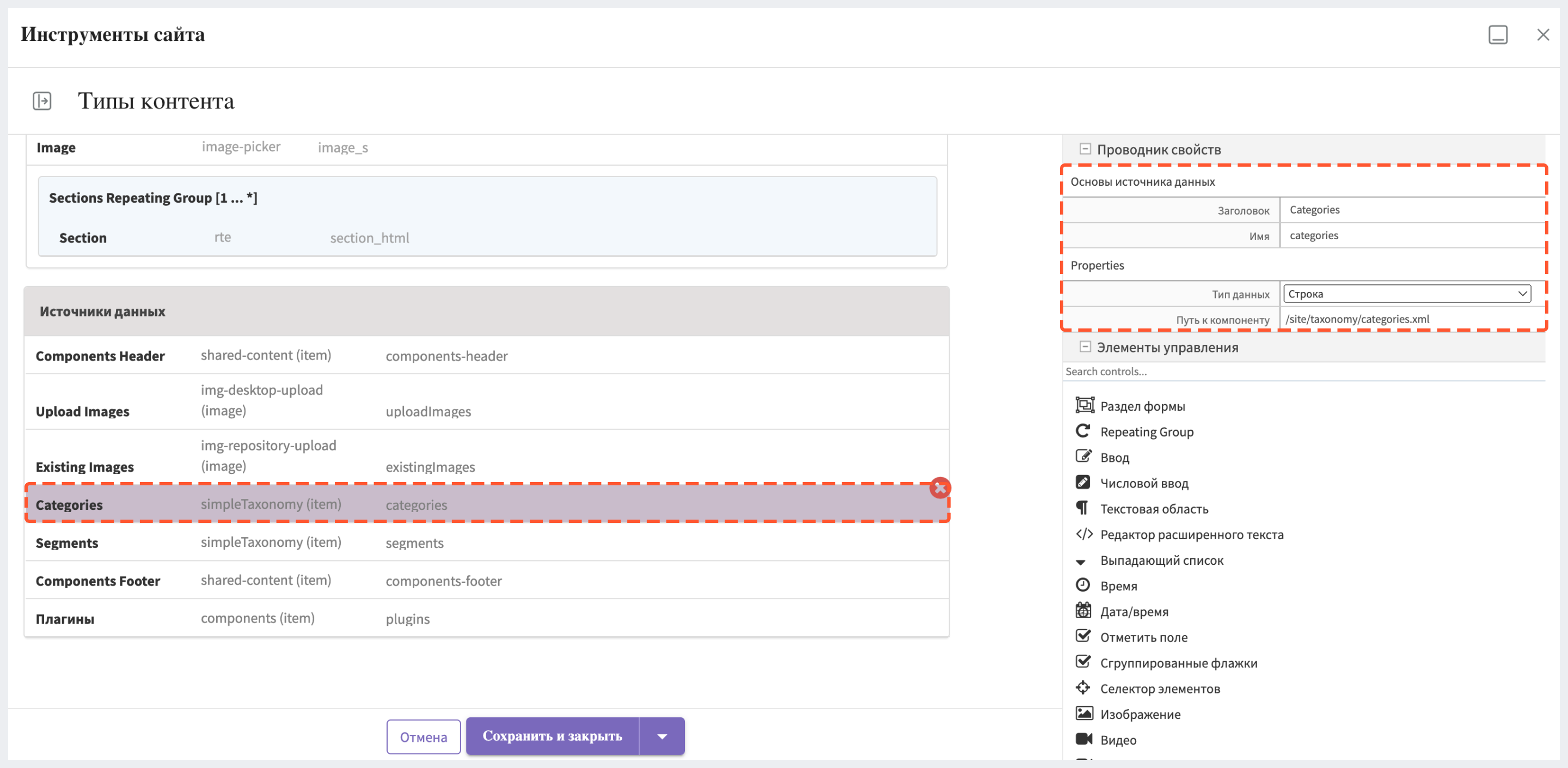
Для создания фасетного поиска необходимо выполнить следующие шаги:
- Интегрировать соответствующие агрегации в запрос поиска.
- Обработать агрегации, полученные из ответа поиска.
- Отобразить фасеты на странице результатов поиска.
Добавление агрегаций в запрос поиска
Для включения агрегаций в запрос используйте ключ aggs. У каждой агрегации должно быть свое уникальное имя в качестве ключа и конфигурации, основанные на её типе.
Поисковый запрос с использованием агрегаций:
def result = searchClient.search(r -> r
.query(q -> q
.queryString(s -> s
.query(q as String)
)
)
.from(start)
.size(rows)
.aggregations('categories', a -> a
.terms(t -> t
.field(categories.item.value_smv)
.minDocCount(1)
)
)
, Map)
В пример выше включена агрегация типа terms с именем categories, которая вернет все найденные значения для поля categories.item.value_smv, которым присвоена хотя бы 1 статья.
Обработка агрегаций в ответе поиска
Ответ на поисковый запрос будет предоставлять агрегации в поле aggregations. Содержимое каждой агрегации изменяется в зависимости от её типа.
Поисковый ответ с использованием агрегаций:
def facets = [:]
if(result.aggregations()) {
result.aggregations().each { name, agg ->
facets[name] = agg.sterms().buckets().array().collect{ [ value: it.key(), count: it.docCount() ] }
}
}
В примере выше агрегации извлекаются из объекта ответа в простую карту. Этот пример предполагает, что все агрегации являются типа terms и извлекают ключ и docCount для каждого идентифицированного значения (называемого "buckets" в Search).
Запрос на все существующие статьи может выглядеть примерно так:
"facets":{
"categories":[
{ "value":"Entertainment", "count":3 },
{ "value":"Health", "count":3 },
{ "value":"Style", "count":1 },
{ "value":"Technology", "count":1 }
]
}
Если повторно запустить запрос с фильтром по категории "Развлечения", он вернет ровно три статьи. Последующие запросы будут генерировать новые фасеты на основе этих статей. Этот метод позволяет пользователям эффективно уточнять результаты и находить более релевантные данные с минимальными усилиями.
Отображение фасетов на страницах результатов поиска
Отображение фасетов зависит от используемой технологии представления информации. Это может быть реализовано с использованием Freemarker или Single Page Application (SPA) с такими фреймворками, как Angular, React или Vue. В качестве примера мы будем использовать шаблоны Handlebars, которые будут отображаться с помощью jQuery.
Шаблоны страниц результатов поиска:
<script id="search-facets-template" type="text/x-handlebars-template">
{{#if facets}}
<div class="row uniform">
{{#each facets}}
<div class="3u 6u(medium) 12u$(small)">
<input type="checkbox" id="{{value}}" name="{{value}}" value="{{value}}">
<label for="{{value}}">{{value}} ({{count}})</label>
</div>
{{/each}}
</div>
{{/if}}
</script>
<script id="search-results-template" type="text/x-handlebars-template">
{{#each articles}}
<div>
<h4><a href="{{url}}">{{title}}</a></h4>
{{#if highlight}}
<p>{{{highlight}}}</p>
{{/if}}
</div>
{{else}}
<p>No results found</p>
{{/each}}
</script>
Мы используем шаблоны для отображения результатов после выполнения поиска:
$.get("/api/search.json", params).done(function(data) {
if (data == null) {
data = {};
}
$('#search-facets').html(facetsTemplate({ facets: data.facets.categories }));
$('#search-results').html(articlesTemplate(data));
});
Последний шаг включает в себя запуск нового поиска, когда пользователь выбирает одно из значений в фасетах:
$('#search-facets').on('click', 'input', function() {
var categories = [];
$('#search-facets input:checked').each(function() {
categories.push($(this).val());
});
doSearch(queryParam, categories);
});
Мультииндексный запрос
DC CMS поддерживает запрос нескольких поисковых индексов в одном запросе.
Для поиска как на вашем сайте, так и в дополнительных индексах отправьте запрос на поиск, включив в него список индексов или алиасов (указателей на индекс), разделенных запятой. Это действие позволит исследовать ваш сайт вместе с указанными индексами.
Важно отметить, что все остальные индексы или алиасы, в которых осуществляется поиск, должны быть предварительно добавлены к имени сайта в формате SITENAME_{external-index-name}. Однако при отправке запроса префикс SITENAME_ следует исключить из других индексов или алиасов.
DC CMS поддерживает различные параметры запросов поиска, включая:
indices_boostsearch_typeallow_no_indicesexpand_wildcardsignore_throttledignore_unavailable
Внедрение поисковых подсказок (Type-ahead service)
В этом разделе мы рассмотрим, как использовать запрос для предоставления предложений-подсказок по мере ввода данных пользователем.
Создание сервиса
Разработайте REST-сервис, который возвращает предложения-подсказки, основанные на контенте вашего сайта.
Требования:
- Сервис использует текущий поисковый запрос пользователя и находит похожий контент
- Сервис возвращает результаты в виде списка строк
Чтобы создать REST-эндпоинт, разместите указанный файл Groovy в вашей папке со скриптами:
import ru.dc.cms.sites.editorial.SuggestionHelper
// Obtain the text from the request parameters
def term = params.term
def helper = new SuggestionHelper(searchClient)
// Execute the query and process the results
return helper.getSuggestions(term)
Вам также нужно создать вспомогательный класс в папке /scripts:
package ru.dc.cms.sites.editorial
import org.elasticsearch.client.elasticsearch.core.SearchRequest
import ru.dc.cms.search.elasticsearch.client.ElasticSearchClientWrapper
class SuggestionHelper {
static final String DEFAULT_CONTENT_TYPE_QUERY = "content-type:\"/page/article\""
static final String DEFAULT_SEARCH_FIELD = "subject_t"
ElasticSearchClientWrapper searchClient
String contentTypeQuery = DEFAULT_CONTENT_TYPE_QUERY
String searchField = DEFAULT_SEARCH_FIELD
SuggestionHelper(searchClient) {
this.searchClient = searchClient
}
def getSuggestions(String term) {
def queryStr = "${contentTypeQuery} AND ${searchField}:*${term}*"
def result = searchClient.search(SearchRequest.of(r -> r
.query(q -> q
.queryString(s -> s
.query(queryStr)
)
)
), Map)
return process(result)
}
def process(result) {
def processed = result.hits.hits*.getSourceAsMap().collect { doc ->
doc[searchField]
}
return processed
}
}
После создания этих файлов и перезагрузки контекста сайта вы можете протестировать REST-эндпоинт из браузера.
Создание пользовательский интерфейса
Создайте интерфейс с использованием HTML, JavaScript и AJAX.
Требования:
- отправка запроса на сервер для мгновенных результатов по мере ввода пользователем
- отображение результатов и предложение вариантов на основе потенциального запроса пользователя
- для оптимизации производительности не запускать запрос при каждом нажатии клавиши; вместо этого накапливать нажатия клавиш пользователем и отправлять запрос, когда размер пакета (batch size) достигнут или когда пользователь прекращает ввод
Вы также можете интегрировать существующую библиотеку или фреймворк, предоставляющий компонент автозаполнения. Например, для использования компонента автозаполнения jQuery UI Autocomplete необходимо указать соответствующий REST-эндпоинт в конфигурации.
$('#search').autocomplete({
// Wait for at least this many characters to send the request
minLength: 2,
source: '/api/1/services/suggestions.json',
// Once the user selects a suggestion from the list, redirect to the results page
select: function(evt, ui) {
window.location.replace("/search-results?q=" + ui.item.value);
}
});